ChatGPT vs Me: As a Children's Authors
For all the right reasons, large language models have taken the world by storm! It’s pretty impressive what ChatGPT can do - unprecedented coherence, relevance and tone of delivery for a synthetic text generation. Well done OpenAI!
I have to admit I have strongly resisted the urge to use it for purposes beyond joy, and exploration. It's been very hard to abstain, especially because I am extremely passionate about AI and also I work in AI. I truly, madly, deeply, utterly fear that we, as a community of carers of young people, are simply NOT ready for it! It’s the infancy state of due diligence to understand the societal implications and governance around it that scares me the most. I fear that while we, the grown-ups, are probably ready and raring to go at it, it’s our younger generations who are not at all ready for it. Once this genie is out of the bottle, out is just the way! And it’s the repeat of our social media fiasco all over again. Perhaps I am coming from a dark place of seeing how exponentially easily our kids are getting social media bullied and exploited with authorities still scrambling even after the fact on how to contain it!
On a lighter note, selfishly speaking, I also fear depleting my creative and critical thinking abilities in favour of convenience and productivity. If Darwin’s theory is anything to go by, that’s one human talent we should preserve and reinforce, I think. Did I hear you say “But you can still be critical of the presented text?”? Sure, but we are also a Large Language Model in many ways :) - we get biased and we are lazy. Is not laziness the inspiration for many useful inventions of our times?
As a mother of young kids and as someone who believes in lifelong learning, I made a tiny effort last year to write chapter books for early readers covering the discoveries of the great scientists of our past and present. In my debut release, I featured Sir Isaac Newton’s discoveries in a book titled “Curious Cassie's beach ride quest: A Celebration of Isaac Newton's Discoveries”. I tested the book on a sample of 5 kids all ranging from 6-7 years and observed extreme enthusiasm and an increased number of questions thereafter. Mission accomplished, eh?
I failed this morning! I failed to resist the chatGPT urge to see what it would write instead. So here’s Me vs chatGPT, a debut author vs a stochastic parrot:
ChatGPT vs Me: Show me the script
ChatGPT
Prompt
Write a chapter book for 6 year old kids
ChatGPT's Response
Chapter 1: The Magical Forest
It was a beautiful day in the magical forest. The sun was shining and the birds were singing. The trees were tall and green, and the flowers were blooming.
In the center of the forest was a small cottage, where a young girl named Lily lived with her parents. Lily was six years old, and she loved to explore the forest.
One day, while out on a walk, Lily stumbled upon a strange and magical place. It was a clearing filled with glittering diamonds and sparkling jewels.
"Wow!" exclaimed Lily. "I've never seen anything like this before!"
As she reached out to touch one of the diamonds, a bright light shone and a magical fairy appeared before her.
"Hello, Lily," said the fairy. "I am the guardian of the forest, and I have been waiting for you. You have a very special task to complete."
"Me?" asked Lily. "What can I do?"
"There is a wicked witch who has been causing trouble in the forest," explained the fairy. "She has been turning all of the animals into stone, and we need your help to stop her."
"I'll do it!" said Lily, determined to help the animals.
Chapter 2: The Wicked Witch
Lily set out on her journey to find the wicked witch. She followed the fairy's instructions and travelled deep into the forest.
As she walked, she saw that the trees were no longer green and the flowers had withered away. It was clear that the witch had been causing destruction wherever she went.
Finally, Lily came to a dark and gloomy castle. She knew this was where the witch lived.
She tiptoed through the castle, trying not to make a sound. She could hear the witch cackling in the next room.
Lily peeked through the door and saw the witch stirring a bubbling pot. She had a long, crooked nose and sharp, pointed teeth.
"Ah-ha!" shouted the witch, turning to face Lily. "I've been expecting you, little girl. You won't be able to stop me from turning all of the animals into stone!"
But Lily was not afraid. She remembered the fairy's words and knew she had to be brave.
"I won't let you harm any more animals!" said Lily, standing up to the witch.
The witch cackled and raised her wand, but Lily was quick. She grabbed a nearby broom and swung it at the witch, knocking the witches wand out of her hand.
The witch let out a cry of rage and fled the castle, leaving Lily to save the animals.
Chapter 3: The Great Celebration
With the witch gone, Lily was able to use her magic to turn the animals back to normal. The forest was filled with joy and celebration.
The fairy thanked Lily for her bravery and offered to grant her one wish.
"I wish for the forest to always be a happy and safe place," said Lily.
The fairy nodded and waved her wand, granting Lily's wish. From then on, the magical forest was filled with happiness and peace.
Lily returned home to her parents, who were overjoyed to see her safe and sound. They threw a great celebration in her honour, and the whole forest came to join in the fun.
Lily knew that she would always treasure her adventure in the magical forest, and she hoped to have many more adventures in the future.
Verdict
Very impressive choice of theme, tone and word selection. It did not give me a title, so I asked to name the title and it responded with "The Brave Explorer: A Magical Adventure in the Forest." Very cool!
Prompt
Write a chapter book for 6 year old kids on STEM
ChatGPT's Response
Chapter 1: The Science Fair
It was a beautiful day in the town of Maplewood, and Lily was excited for the annual science fair at her school. She had been working on her project for weeks, and she couldn't wait to show it off.
Lily's project was a model of the solar system, complete with miniature planets made out of clay and a sun made out of papier-mâché. She had worked hard to make sure everything was accurate and to explain the orbits of the planets in a way that other kids could understand.
As the science fair began, Lily set up her project at her table and waited for the judges to come by. She was a little nervous, but she knew she had done her best.
The judges were impressed by Lily's project and asked her lots of questions about the solar system. Lily was happy to answer and explain what she had learned.
In the end, Lily's project won first place in the science fair! She was so proud of herself and couldn't wait to show her parents.
Chapter 2: The Technology Club
After the science fair, Lily's teacher, Mrs. Kim, asked her if she would like to join the Technology Club at school. Lily was excited at the chance to learn more about science and technology, and she eagerly accepted.
In the Technology Club, Lily and her friends learned about all sorts of different topics, from coding and robotics to engineering and renewable energy. They built and programmed robots, designed and tested bridges, and learned about how solar panels work.
Lily loved the Technology Club and couldn't wait to go each week. She learned so much and had a lot of fun doing it.
Chapter 3: The Engineering Competition
One day, Mrs. Kim announced that the Technology Club was going to participate in an engineering competition. The students would have to design and build a Rube Goldberg machine, a complicated contraption that could perform a simple task in a creative and convoluted way.
Lily and her friends were up for the challenge and set to work planning and building their machine. They worked together as a team, using their knowledge of physics, engineering, and problem-solving to make their machine work.
Finally, the day of the competition arrived. Lily and her friends were nervous but excited to see how their machine would perform.
As they presented their machine to the judges, it worked perfectly, performing the simple task with a series of intricate steps. Lily and her friends were thrilled when they were announced as the winners of the competition!
Chapter 4: The Future Scientists
After the engineering competition, Lily and her friends in the Technology Club knew that they wanted to continue exploring science and technology in the future. They were already thinking about new projects and competitions they could participate in.
Lily knew that she wanted to be a scientist when she grew up, and she was grateful for all of the opportunities she had had to learn and explore in the Technology Club.
She knew that no matter what she did in the future, she would always have a passion for science and technology and the desire to learn more.
Verdict
Nice plot setting, nice choice of theme, and context. Nice job. I find it's very peripheral, explaining a lot about the setting but nothing about science. Maybe it’s my prompt. Let's give it another go.
Prompt
Write a 6-7 year old kids’ book on Sir Isaac Newton's discoveries with Cassie as a protagonist
ChatGPT's Response
Cassie and the Apple Tree
Cassie was a curious little girl who loved to learn about the world around her. One day, she was walking through her backyard when she saw an apple fall from a tree.
"Hmm, I wonder why that happened?" Cassie thought to herself. She climbed up the tree to see if she could find out more.
As she reached the top, she saw a man standing under the tree. It was Sir Isaac Newton! Cassie had heard of him before. He was a very smart man who had made many important discoveries.
"Hello, Cassie," Sir Isaac said. "I see you're curious about the apple."
"Yes, I am," Cassie replied. "Why did it fall to the ground?"
"Ah, that's a good question," Sir Isaac said. "I figured out that there is a force called gravity that pulls objects towards the ground. That's why the apple fell."
Cassie was amazed. "Wow, that's so cool!" she exclaimed.
Sir Isaac smiled. "I also made many other discoveries," he told Cassie. "Like the laws of motion, which explain how objects move and change speed. And I invented calculus, which helps us understand how things change over time."
Cassie's head was spinning with all this new information. She couldn't wait to learn more about Sir Isaac's discoveries.
"Thank you for telling me all about this, Sir Isaac," Cassie said. "I can't wait to learn more!"
"You're welcome, Cassie," Sir Isaac replied. "I'm glad you're interested in learning. Remember, the more you learn, the more you'll discover about the world around you."
Cassie smiled and climbed back down the tree, excited to keep learning and discovering new things.
Verdict
Nice choice of words, context is spot on, and tone of delivery is nice too. Some of the phrases are spot on. "Wow, that's so cool!" she exclaimed.” is something I have used too.
Apple and Newton are joined together forever. Cliché, my dear parrot! Cliché! Well done still. Maybe I like more challenges given to the kids, but I still feel it’s too shallow and lacks details. Let’s give it more work and see what ChatGPT does.
Prompt
Write a 6-7 year old kids chapter book on Sir Isaac Newton's discoveries with Cassie as the protagonist with illustrations
ChatGPT's Response
Chapter 1: Cassie and the Apple Tree
[Illustration: Cassie is standing in her backyard, looking up at an apple falling from a tree.]
Cassie was a curious little girl who loved to learn about the world around her. One day, she was walking through her backyard when she saw an apple fall from a tree.
"Hmm, I wonder why that happened?" Cassie thought to herself. She climbed up the tree to see if she could find out more.
[Illustration: Cassie is climbing up the tree, with a determined look on her face.]
As she reached the top, she saw a man standing under the tree. It was Sir Isaac Newton! Cassie had heard of him before. He was a very smart man who had made many important discoveries.
"Hello, Cassie," Sir Isaac said. "I see you're curious about the apple."
"Yes, I am," Cassie replied. "Why did it fall to the ground?"
"Ah, that's a good question," Sir Isaac said. "I figured out that there is a force called gravity that pulls objects towards the ground. That's why the apple fell."
[Illustration: Sir Isaac is pointing to a diagram of the earth and the apple, with an arrow labeled "gravity" pointing from the earth to the apple.]
Cassie was amazed. "Wow, that's so cool!" she exclaimed.
Chapter 2: The Laws of Motion
After learning about gravity, Cassie couldn't wait to find out more about Sir Isaac's discoveries. She asked him to tell her more.
"I also made many other discoveries," Sir Isaac said. "Like the laws of motion, which explain how objects move and change speed."
[Illustration: Sir Isaac is holding a book labeled "Laws of Motion," with diagrams of moving objects in the background.]
Cassie was fascinated. Sir Isaac explained that there are three laws of motion:
Objects at rest stay at rest, and objects in motion stay in motion with the same speed and direction, unless acted upon by a force.
The force needed to change the motion of an object is equal to the mass of the object times its acceleration.
For every action, there is an equal and opposite reaction.
[Illustration: Sir Isaac is pointing to a chalkboard with the three laws of motion written on it, with illustrations of objects in motion on either side.]
"These laws help us understand how objects move and behave in the world around us," Sir Isaac said.
Chapter 3: Calculus
Cassie couldn't believe how much she was learning from Sir Isaac. She asked him if there was anything else he had discovered.
"Yes, I also invented calculus," Sir Isaac said. "It helps us understand how things change over time."
[Illustration: Sir Isaac is holding a book labeled "Calculus," with a diagram of a curve on the cover.]
Cassie was a little confused. "What do you mean?" she asked.
Sir Isaac explained that calculus is a way of studying how things change. "For example, we can use calculus to understand how fast a ball is rolling down a hill, or how fast a plant is growing," he said.
[Illustration: Sir Isaac is pointing to a graph with a curve on it, with a ball rolling down a hill in the background.]
Cassie was amazed. "That's so cool!" she exclaimed.
Chapter 4: The End
After learning all about Sir Isaac's discoveries, Cassie was even more excited to keep learning and discovering new things. She thanked Sir Isaac for all of his help and said goodbye.
"Remember, Cassie," Sir Isaac said as she walked away. "The more you learn, the more you'll discover about the world around you."
[Illustration: Cassie is waving goodbye to Sir Isaac, with a big smile on her face.]
Cassie smiled and waved, excited to keep exploring and learning. She knew that there were so many more mysteries to solve and discoveries to be made.
Verdict
I love this line "The more you learn, the more you'll discover about the world around you." ChatGPT, You can be nice if not exploited! I liked the mention of calculus. It’s a brilliant thought but I stopped at algebra in my book!
However, I remain unsatisfied given the lack of detail and meat around the topic. I feel, for now, human writing is more creative, rich and informative! I am glad that’s the way it is!
Me! Me!
Title: Curious Cassie's beach ride quest: A Celebration of Isaac Newton's Discoveries
[Illustration: Cassie is riding in a car with her family! She is buzzing with interesting curious keywords like Wow, What, How, When, Where! Sir Isaac is featured in the book.]
Here's a sample of my book. It shows 1st chapter of the 3-chapter book.

I am just a debut author, writing out of hobby. I am profoundly impressed by authors who have written brilliant books to teach, guide and shape our children. I hope we will continue to create far-enriched content to shape ourselves and our future with or without AI - just as long as we are in control.
Thanks a lot for reading! If you ever see any value in spreading the word about my book or procuring it for your loved ones then please do so, I would be thrilled!
Disclaimer: This is a personal post. Views shared are my own and do not represent my employers.
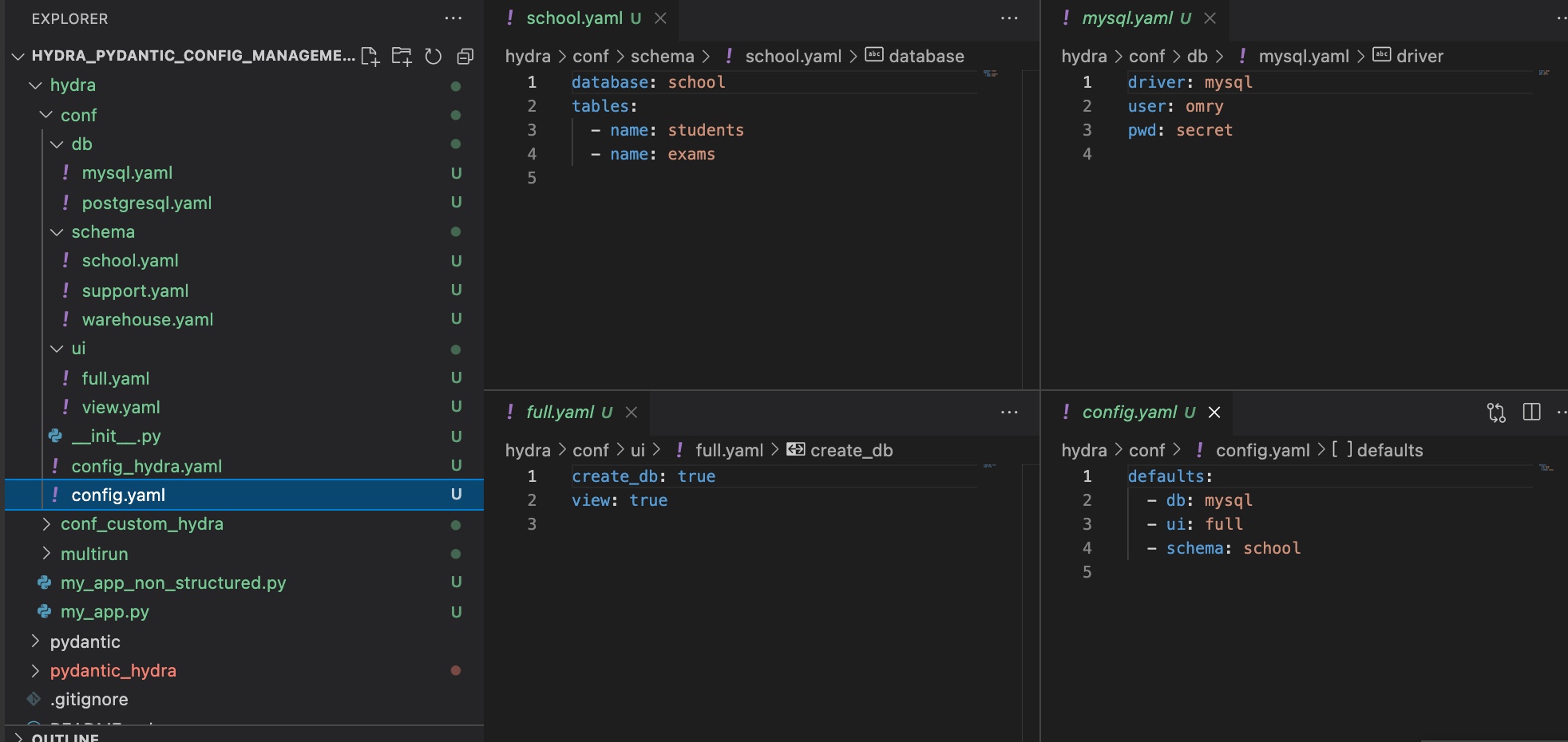 Example hierarchical hydra config.
Example hierarchical hydra config.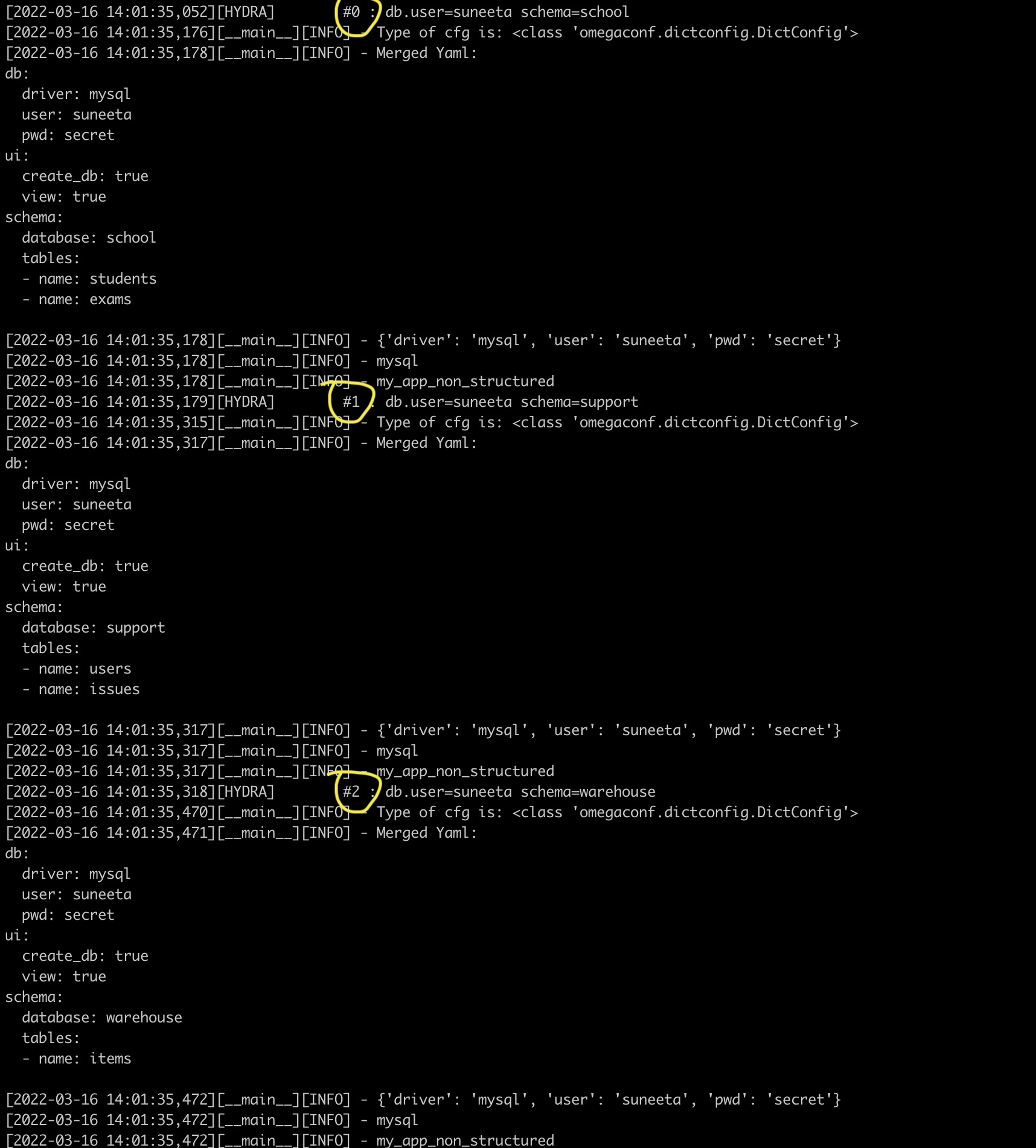 Example Of multi-runs.
Example Of multi-runs.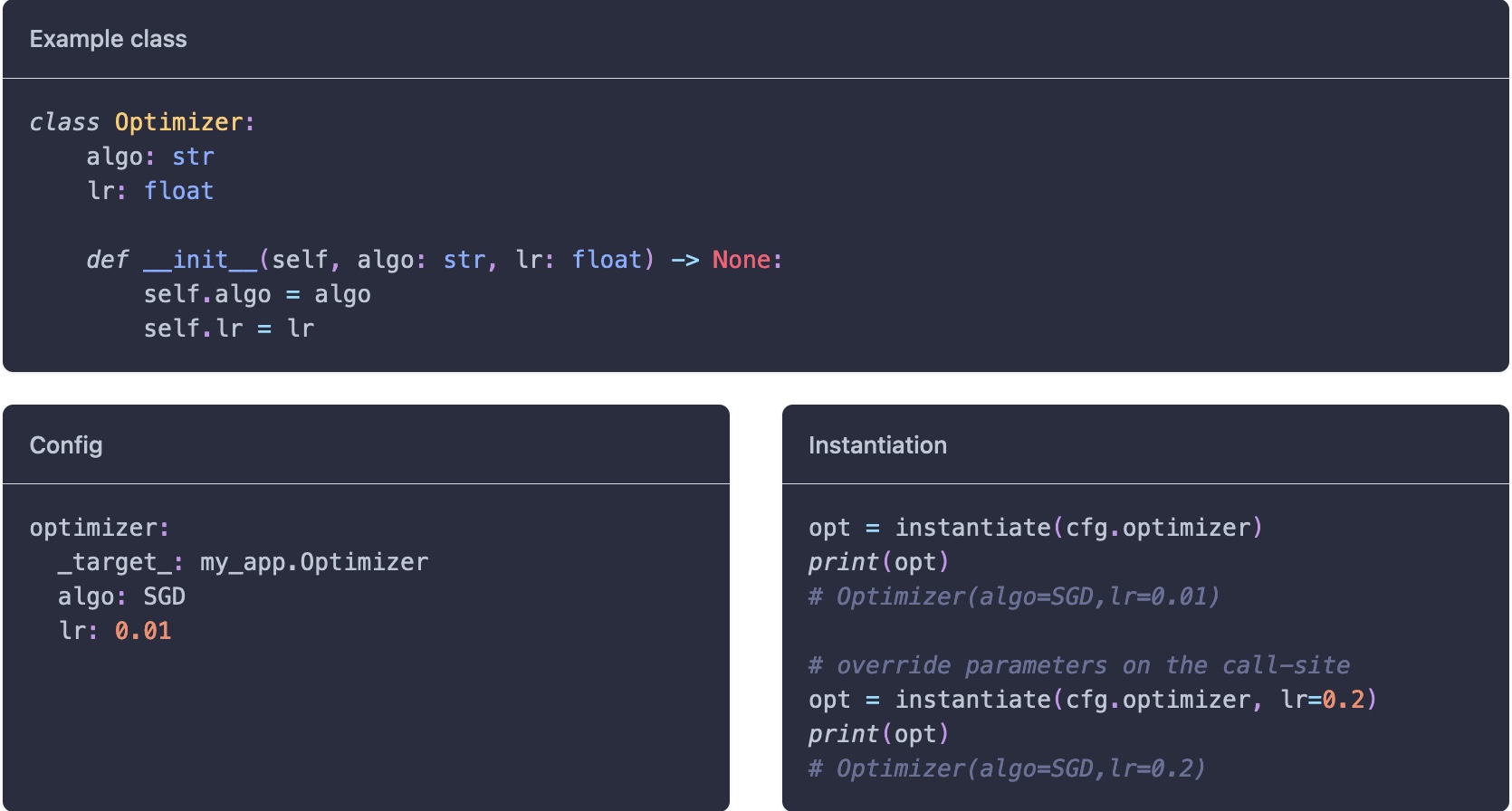 Example Of instantiate objects.
Example Of instantiate objects.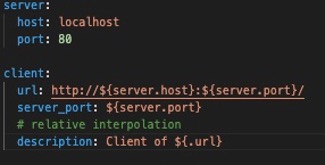 Example Of instantiate objects.
Example Of instantiate objects.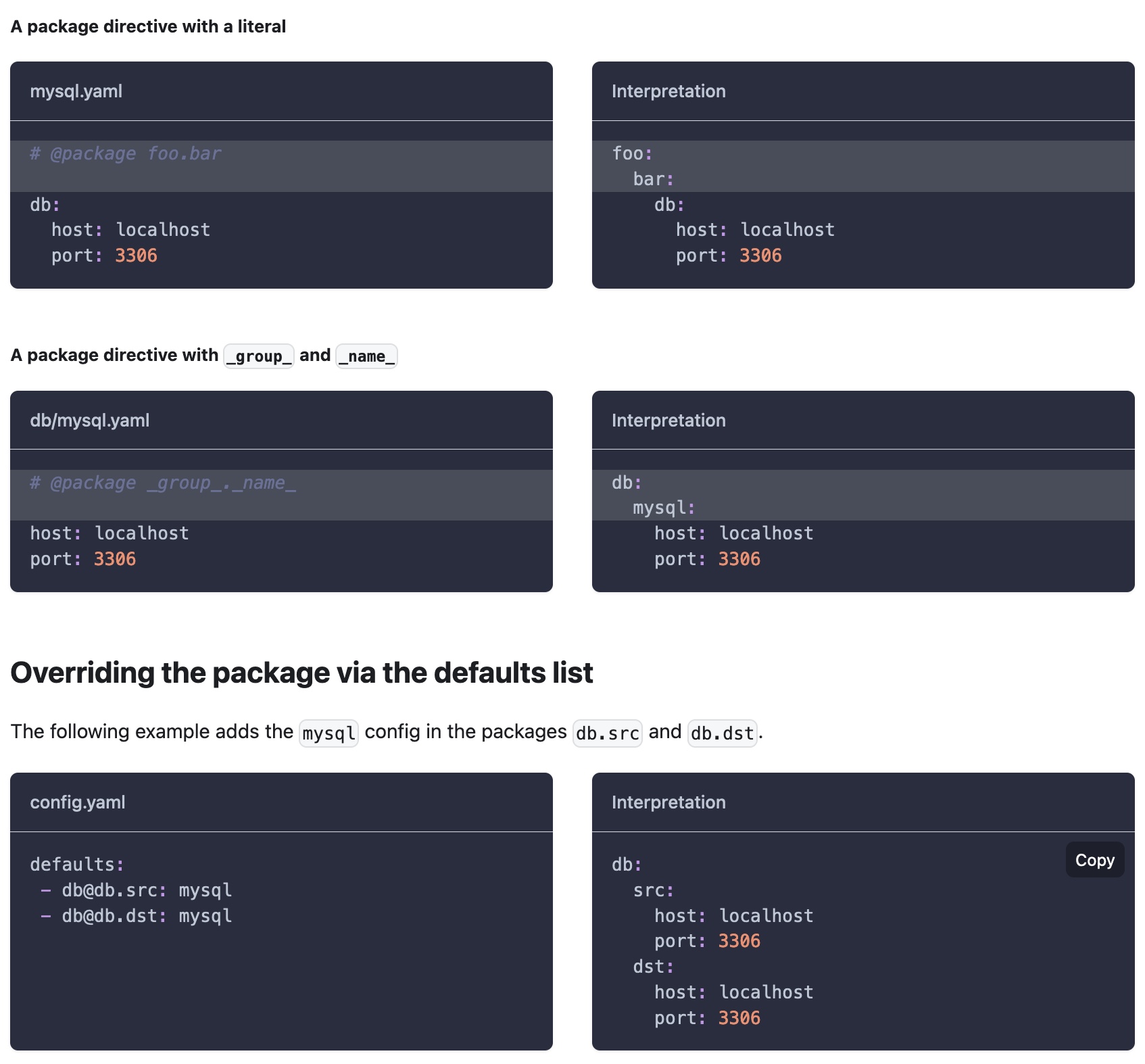 Example Of directives to rewrite config specifications.
Example Of directives to rewrite config specifications.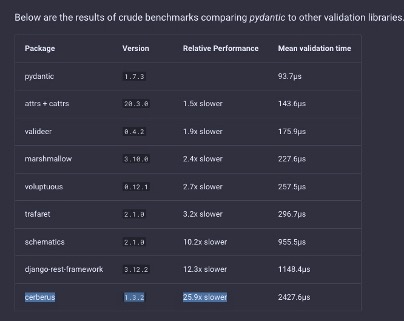 Hydra's benchmarks.
Hydra's benchmarks.